1. More on Inverse Rendering
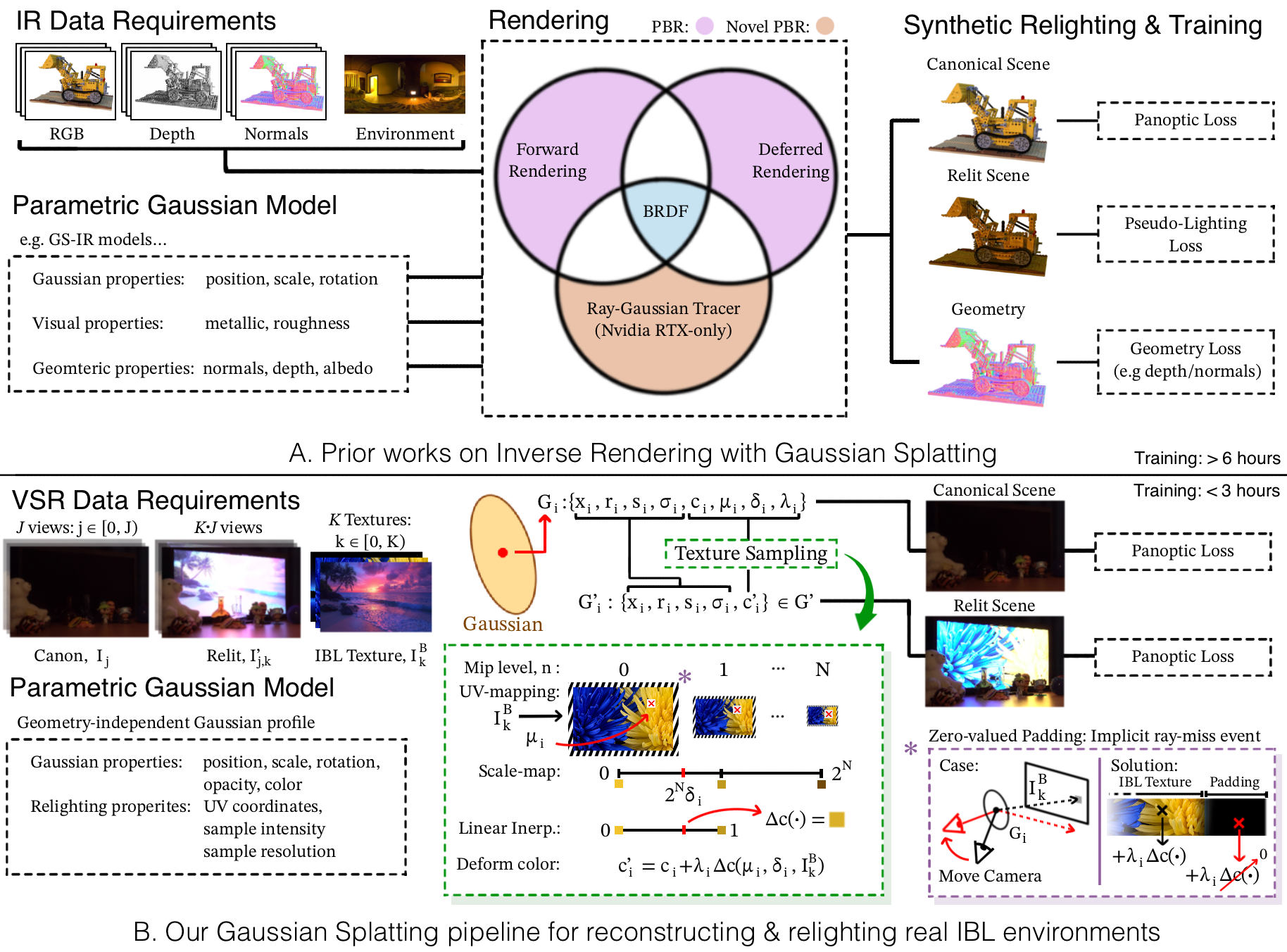
In the figure above we compare the IR and VSR data requirements, generic Gaussian primitives, rendering pipeline and training scheme. There are clear differences regarding representation, data needs and loss functions. Notably, our method acts independent of Gaussian geometry, does not rely on priors and can be trained using the simple panpotic loss function. Futhermore, our method does not require custom CUDA/RTX code and uses the well documented gsplat rasterizer.
2. Unconstrained Illumination in Photo Collections (UIPC)
UIPC research focuses on 3D scene relighting for unconstrained photo collections. This mainly involves reconstructing landmarks from data that is scraped from social media websites, so contains seasonal appearance captured over different periods of the day and year. Here, 3D relighting pipelines are expected to interpolate between the variable lighting as well as deal with various geometric capture conditions. UIPC shares similarity with our VSR paradigm, as VSR also ingests a dataset with variable light conditions. The difference lies with the research objective, as UIPC pipelines mainly focus on dealing with explicit geometric uncertainties related to the unconstrained photo collections. For example, the XX landmark dataset is composed of images scraped from social media so the data contains distractors, like transient humans or vehicles or animals. Instead, our method aims to capture implicit geometric phenomena to support unseen lighting conditions, i.e. when a new background texture is introduces. As a result, UIPC research is mainly focused on dealing with temporal distractors that arise from, As the main paradigm of VSR regards the approach to IBL texture sampling, there is not much inspiration that can gained from comparing VSR to UIPC.
3. Gaussian Splatting Texture Enhancement (GTE)
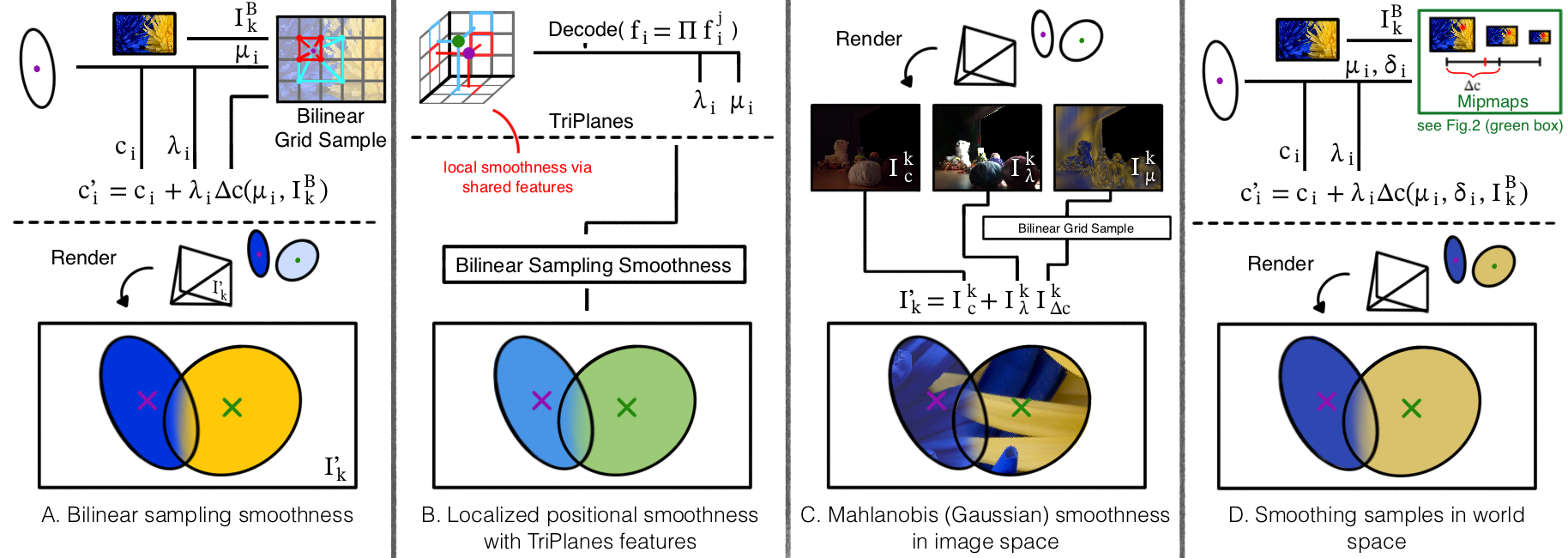
GTE research mainly focuses on anti-aliasing problems for generic scene reconstruction, not relighting. GTE focuses on novel ray-Gaussian intersection schemes that allow for Gaussian sub-sampling - enhancing the expressivity of the scene. Thus, GTE research remains unrelated to the VSR texture sampling. However, TexGS proposes a Gaussian sub-sampling method that samples a ground truth RGBA texture per-Gaussian. TexGS adopts a color deformation scheme akin to dynamic GS reconstruction, replacing the temporal color residual with a view-dependent color residual. Inspired by this work, we extend the deformation model by introducing an intensity parameter that modifies the magnitude of the deformation, independent of IBL texture. This essentially models a static exposure setting, which future work could explore for scene editing applications.